
本記事では、YOLOv5を使用してマスクを着用しているかを識別するモデル構築の方法についてご紹介します。
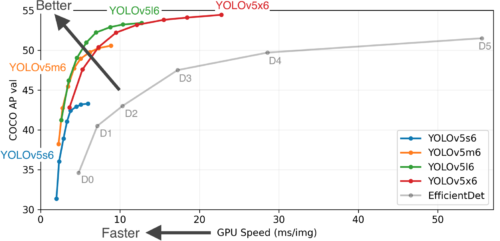
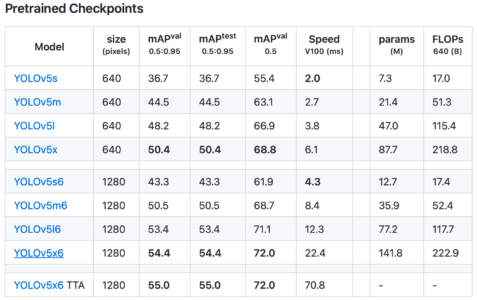
YOLOv5(YouOnlyLookOnce)は、2020年6月に公開された最新の物体検出のモデルになります。精度と演算負荷に応じてYOLOv5s、YOLOv5m、YOLOv5l、YOLOv5xまでの4モデルがあります。大きなモデルになると精度は高くなりますが、処理速度は遅くなります。各モデルの性能は以下の通りです。YOLOv5モデルとEfficientDet(https://arxiv.org/abs/191701.0907)の比較です。
物体検出
画像分類は、1枚の画像に1つの物体が写っており「それが何であるか」を推定します。例えば「この写真に写っているのは0~9の数字のどれか」「この顔写真は女性か男性か」といったことを判別させます。
物体検出では、画像や動画内に1つ以上の物体が写っており、「何」が、「どこ」にあるのかを推定します。各種クラウドサービスでAPIが公開されていますのでデータを準備すれば手軽に物体検出を体験できます。
参考
"Tensorflow Object Detection API"
https://github.com/tensorflow/models/tree/master/research/object_detection
Dataset
マスクの検出器を構築するためには学習データが必要になります。学習データには、画像とバウンディングボックス付きのラベル付きのデータが必要になります。
画像の収集方法は、google画像検索から収集したり自分で写真を撮影をしてその画像をアノテーションツールであるlabellmgを使用し画像に手動で物体の位置(矩形で囲む)と物体の名前(ラベル)の情報を記録することにより、独自のデータセットを構築する方法があります。以下に例を示します。


参考
labellmg:https://github.com/tzutalin/labelImg
Dataset Search:https://datasetsearch.research.google.com
もう一つの方法は、公開されている画像データセットを使用することです。
今回は、https://www.kaggle.com/andrewmvd/face-mask-detectionから学習データセットをダウンロードしてGoogleDriveにダウンロードしました。
ダウンロードされた学習データセットは以下の2つに構成されております。
- images853個の.pngファイル
- annotations853個の.xmlファイル
Google Colabの準備
Googleの画面からドライブを選択します。

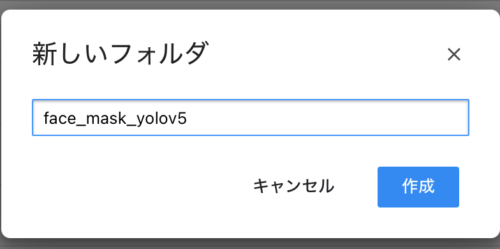
フォルダを作成します。新規/フォルダを選択します。フォルダ名を入力します。今回は「face_mask_yolov5」とします。

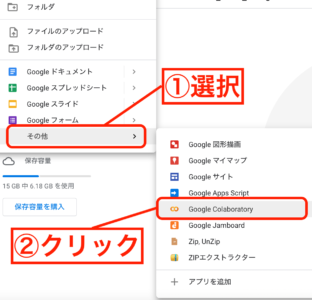
ドライブの新規/その他/Google Colaboratoryを選択して開きます。
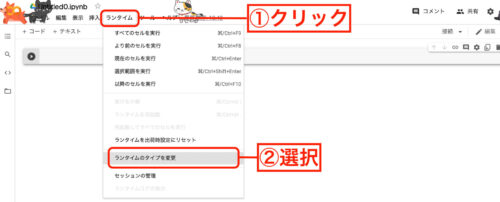
Google Colaboratory上で動かす場合は、ランタイムの設定が必要になります。
今回は、実装するにあたり環境は、GoogleColabを活用しモデル学習時にGPUを使用します。ランタイムから「ランタイムのタイプを変更」を選択し「GPU」を選択します。
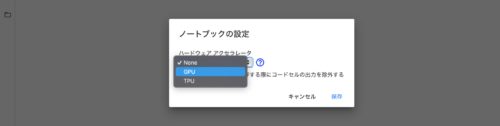
画面で「ハードウェアアクセラレータ」をクリックすると、「None」、「GPU」、「TPU」という選択肢が表示されます。「None」はCPUでの実行環境になっています。簡単なコードであれば「None」、GPUに対応しているのであれば「GPU」、TPUに対応しているのであれば「TPU」を選択することで計算速度を上げることができます。
ただし、GoogleColabを使用する際に気を付ける点は二つあります。
- アイドル状態が90分続くと停止します(使用PCをスリープ状態にしないなど工夫が必要です)
- 連続して使用できる時間は最大12時間です
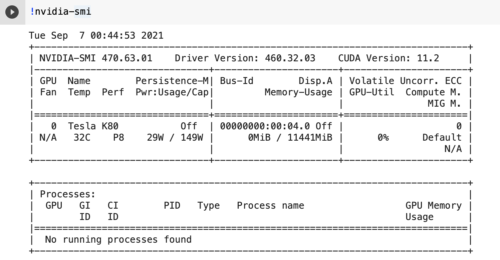
以上、Google Colaboratory上で実行する準備が整いました。
YOLOv5のインストール
YOLOv5のインストールをする前に、以下のコマンドで作業用に作成したフォルダに移動します。
%cd /content/drive/MyDrive/face_mask_yolov5
YOLOv5をgitからダウンロードします。
!git clone https://github.com/ultralytics/yolov5
インストールが完了したらYOLOv5配下に移動します。
%cd yolov5
学習データの準備
Googleドライブ/MyDrive配下に画像データとラベルデータが入っている「face-mask-detection」を追加します。
以下のコマンドを実行してGoogleドライブ/MyDrive/yolov5配下に「Dataset/facemask/Images」「Dataset/facemask/Labels」のフォルダを追加して「Images」フォルダに画像データをコピーします。
!mkdir -p Dataset/facemask/Images
!mkdir -p Dataset/facemask/Labels
!cp -rf /content/drive/MyDrive/face-mask-detection/images/* Dataset/FaceMask/Images
YOLOでは.txt形式で読み込むため、annotationフォルダにある.xmlファイルを.txtファイルに変換する必要があります。
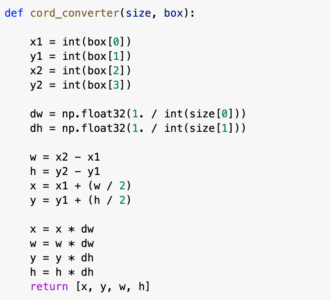
アノテーションの形式を以下に示します。
#<object-class> <x_center> <y_center> <width> <height>
#0:with_mask 1:without_mask 2:mask_weared_incorrect
0 0.40199334593489766 0.5949999867007136 0.31893686950206757 0.29499999340623617
モデルをトレーニングする前にdataファイル内にfacemask.yamlを作成します。学習用画像の場所、検証用画像の場所、ラベルの数、学習データのラベル名を指定します。ファイルは以下のように構成しています。
train: Dataset/images/train
val: Dataset/images/val
#classes
nc : 3
names: ['With_Mask', 'Without_Mask', 'Incorrect_Mask']
モデルの学習
モデルをトレーニングするために、以下の引数を使用してtrain.pyを実行します。
- img:画像サイズ
- batch:バッチサイズ
- epochs:学習回数(指定しない場合は300がデフォルトです)
- data:データ定義ファイル
- cfg:使用する学習モデルを指定する(今回はyolov5x)
- weights:重みファイルを指定(今回はyolov5x.pt)
!python train.py --img 320 --batch 16 --epochs 30 --data /content/drive/MyDrive/face_mask_yolov5/yolov5/data/facemask.yaml --cfg /content/drive/MyDrive/face_mask_yolov5/yolov5/models/yolov5x.yaml --weights yolov5x.pt
学習された重みは、runs/train/exp/weightsにlast.pt、best.ptの2種類のファイルが生成されます。このファイルが学習モデルの重みファイルになり、そのファイルを使用して物体検出を行います。last.ptは、学習のエポック最後の重み、best.ptは、トレーニング中に記録された一番精度の高い重みになります。
学習過程の損失と結果は、results.txt logfileに記録されます。
このログファイルはruns/train/exp/.pngファイルとしてプロットされるため確認することでモデルがどのように実行されたかを確認できます。
モデルの学習が完了したので新規の単一画像、動画でマスクを着用しているか検出できる準備が整いました。
detect.pyを使いパラメータを調整して実行します。検出が完了するとruns/detect/expに結果が生成されます。実行するたびに、新しいフォルダ(exp2、exp3...)が自動で生成されます。
- source:物体検出したい画像のフォルダ、画像のパスを指定
- img:画像サイズ
- conf:閾値(今回は0.4以下は表示しない)
- weights:学習されたモデルの重み
python detect.py --source Dataset/images/test --img-size 320 --conf 0.4 --weights ../yolov5/runs/train/exp/weights/best.pt


また、以下コマンドで撮影した動画の物体検出ができます。検出が完了するとruns/detect/exp2に検出結果が生成されます。
python detect.py --source ../yolov5/face-images/facemaskmovie.mp4 --img-size 320 --conf 0.4 --weights ../yolov5/runs/train/exp/weights/best.pt
GoogleColaboratryでは、以下のコマンドで先述の物体検出した動画を再生できます。
from IPython.display import HTML
from base64 import b64encode
mp4 = open('../runs/detect/exp2/facemaskmovie.mp4', 'rb').read()
data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode()
HTML(f"""
<video width="100%" height="100%" controls>
<source src="{data_url}" type="video/mp4">
</video>""")
Jupiter Notebookで物体検出した動画を再生する場合は、以下のコマンドで再生できます。
from IPython.display import Video
Video('runs/detect/exp2/facemaskmovie.mp4')
以下のコマンドで構築したモデルを使ってWebカメラの映像に対してリアルタイムにマスクを着用しているか識別できます。
python detect.py --source 0 --img-size 320 --conf 0.4 --weights ../yolov5/runs/train/exp/weights/best.pt
ただし、実行前にdetect.pyの一部を編集する必要があります。編集しないで実行すると起動画面を止めることができなくなります。
また、人的ミスで必要なコードを削除してしまう恐れがあるので、編集する前にdetect.pyをコピーして保管しておきましょう。
以下のように編集します。
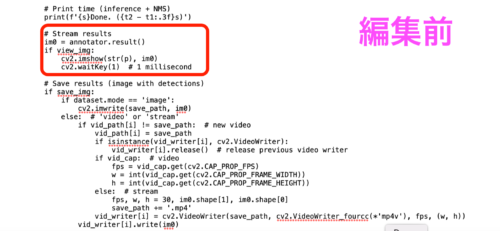
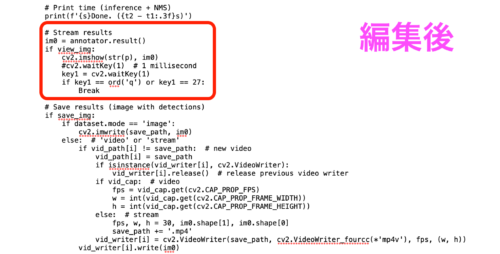
まとめ
今回は、YOLOv5を使ってマスクを着用しているかを識別するモデル構築の方法についてご紹介しました。
ぜひ、独自のデータを使って一度実践してみてください。
